Week 11 [Mon, Oct 28th] - Topics
Guidance for the item(s) below:
While architecture is not of high importance to a small project such as the tP, it is good to know a little bit about it in case you are thrown into a larger project in future.
Introduction
Guidance for the item(s) below:
First, let us learn about multi-level design, a pre-cursor to learning about architecture.
Can explain multi-level design
In a smaller system, the design of the entire system can be shown in one place.
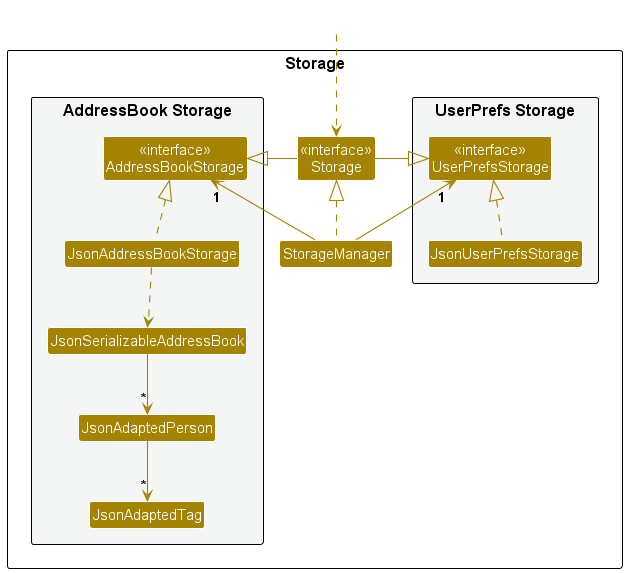
This class diagram of se-edu/addressbook-level2 depicts the design of the entire software.
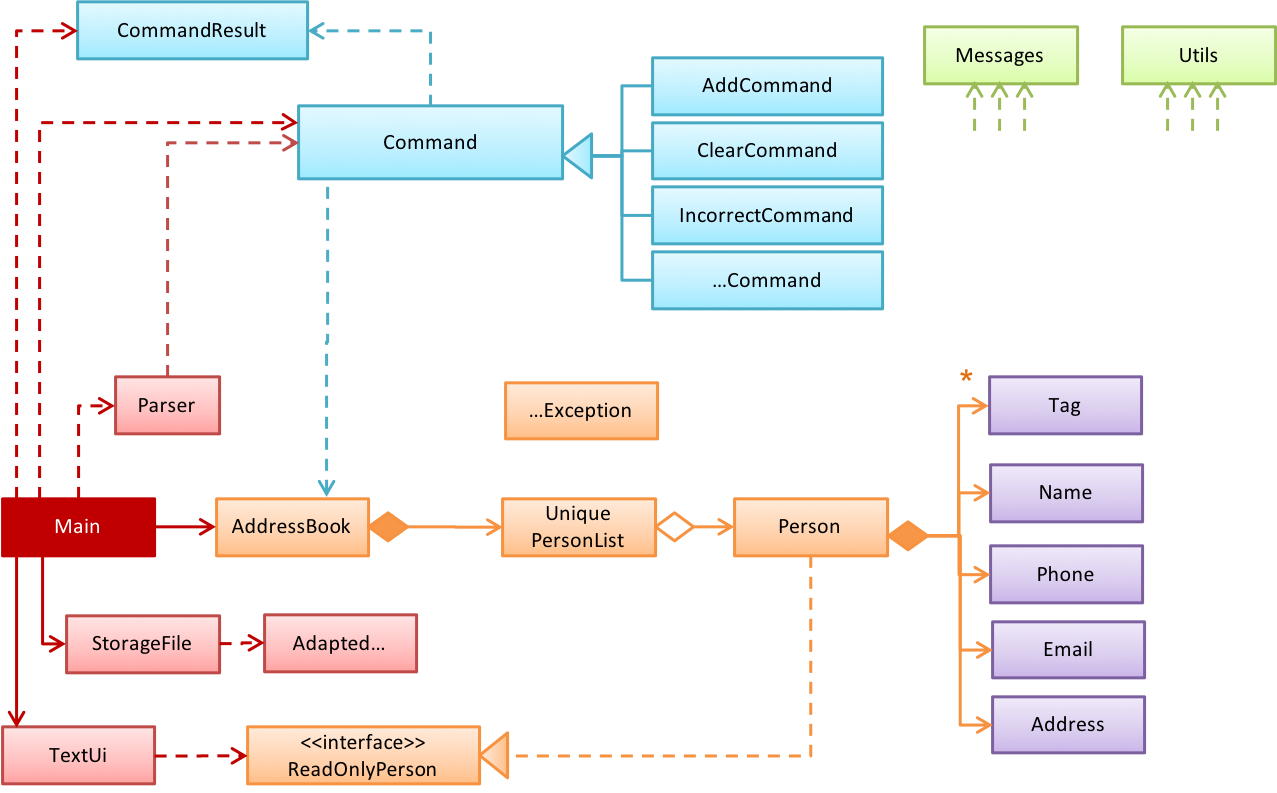
The design of bigger systems needs to be done/shown at multiple levels.
This architecture diagram of se-edu/addressbook-level3 depicts the high-level design of the software.
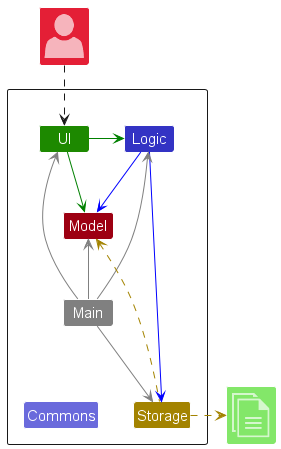
Here are examples of lower level designs of some components of the same software:
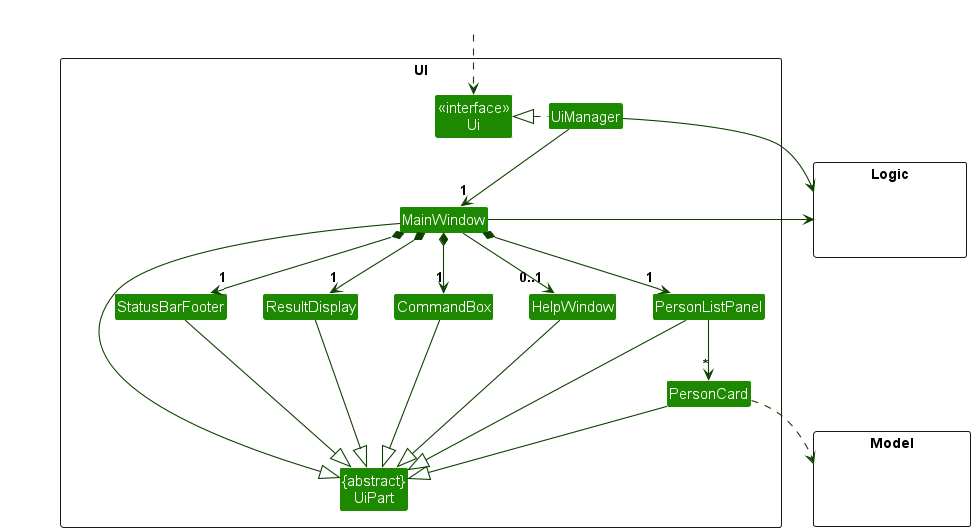
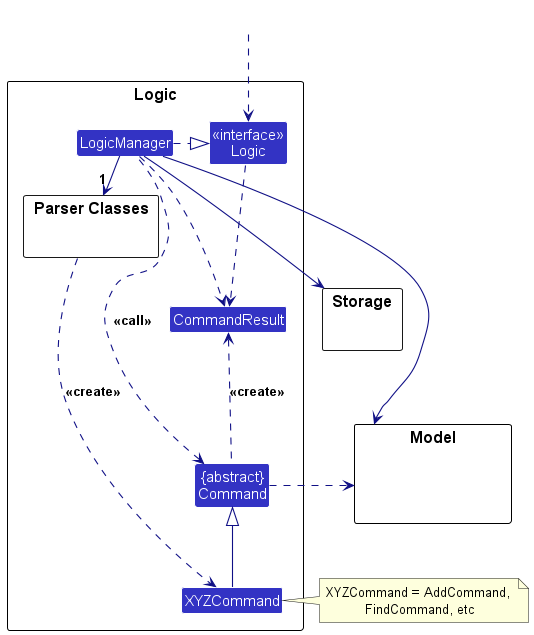
Guidance for the item(s) below:
Now that we know about multi-level design, let us learn about architecture, which is a special case of multi-level design. We also cover architecture diagrams here.
Can explain Software Architecture
The software architecture of a program or computing system is the structure or structures of the system, which comprise software elements, the externally visible properties of those elements, and the relationships among them. Architecture is concerned with the public side of interfaces; private details of elements—details having to do solely with internal implementation—are not architectural. -- Software Architecture in Practice (2nd edition), Bass, Clements, and Kazman
The software architecture shows the overall organization of the system and can be viewed as a very high-level design. It usually consists of a set of interacting components that fit together to achieve the required functionality. It should be a simple and technically viable structure that is well-understood and agreed-upon by everyone in the development team, and it forms the basis for the implementation.
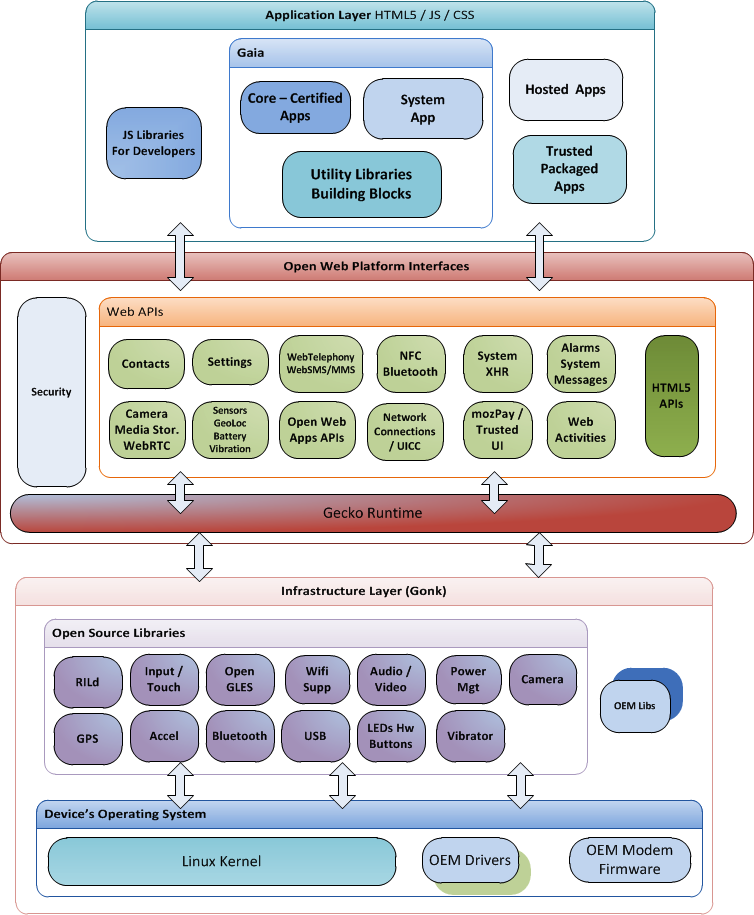
A possible architecture for a Minesweeper game:
 | 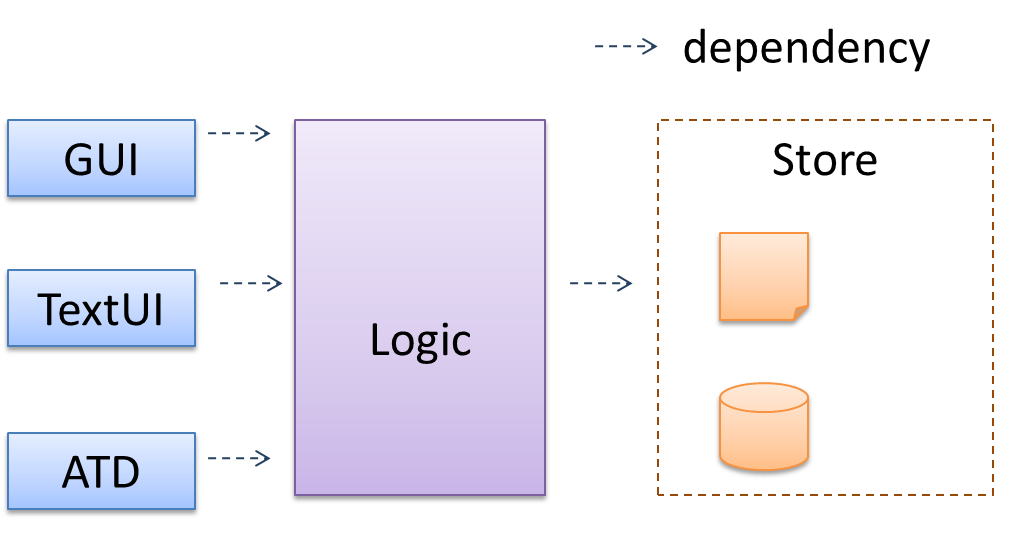 |
Main components:
GUI: Graphical user interfaceTextUi: Textual user interfaceATD: An automated test driver used for testing the game logicLogic: Computation and logic of the gameStore: Storage and retrieval of game data (high scores etc.)
The architecture is typically designed by the software architect, who provides the technical vision of the system and makes high-level (i.e. architecture-level) technical decisions about the project.
Can interpret an architecture diagram
Architecture diagrams are free-form diagrams. There is no universally adopted standard notation for architecture diagrams. Any symbols that reasonably describe the architecture may be used.
Some example architecture diagrams:
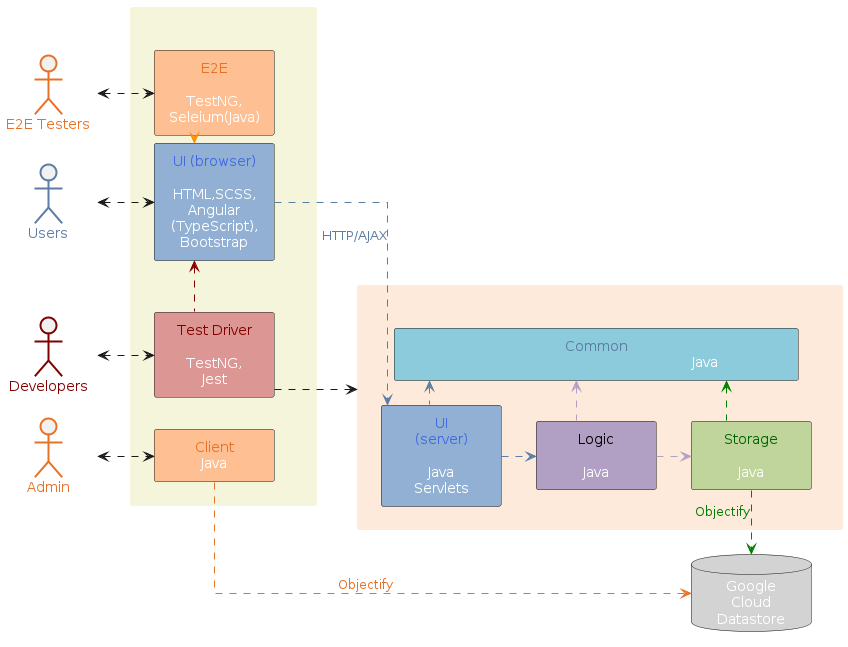


{kind=link}
Guidance for the item(s) below:
The next topic is like 'design patterns at architecture level'. In fact, the MVC pattern you saw earlier comes close to this category too.
Architectural Styles
Can identify n-tier architectural style
In the n-tier style, higher layers make use of services provided by lower layers. Lower layers are independent of higher layers. Other names: multi-layered, layered.
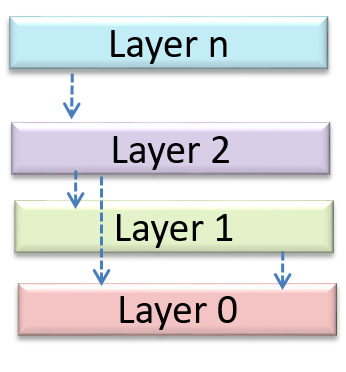
Operating systems and network communication software often use n-tier style.
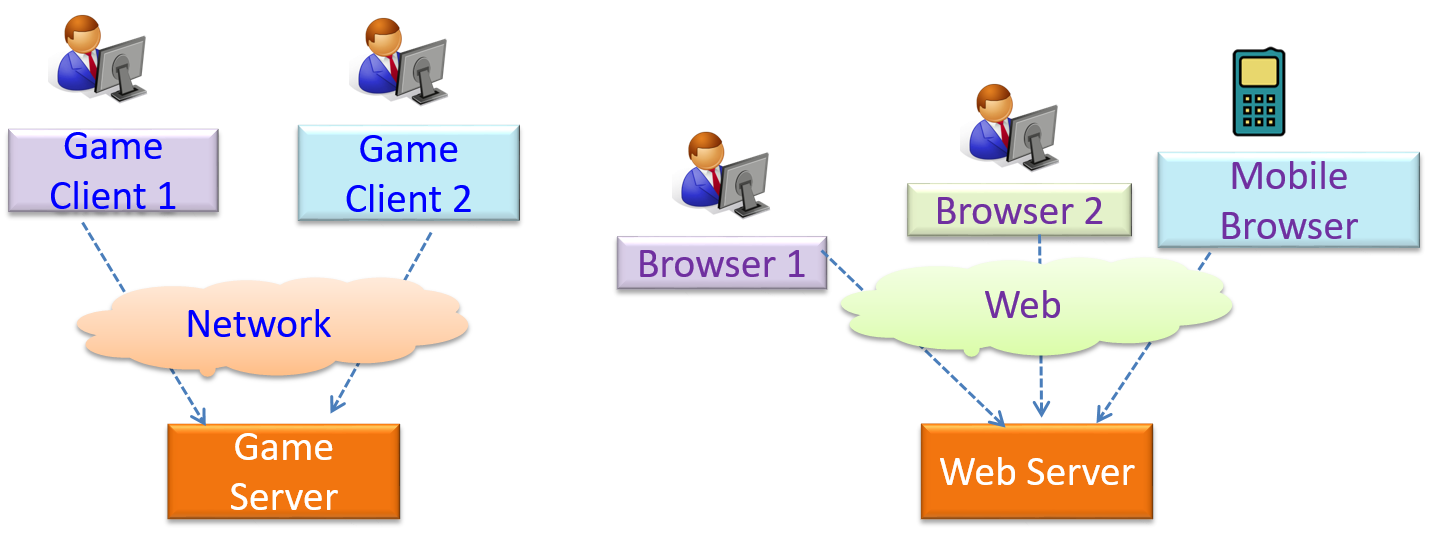
Can identify the client-server architectural style
The client-server style has at least one component playing the role of a server and at least one client component accessing the services of the server. This is an architectural style used often in distributed applications.
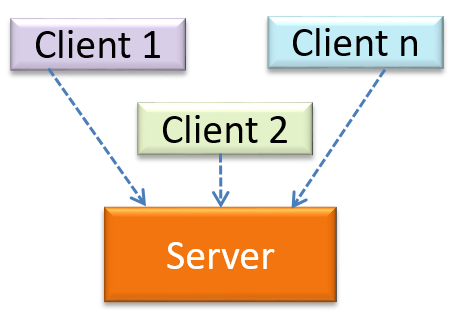
The online game and the web application below use the client-server style.
Guidance for the item(s) below:
As we approach the last part of the tP, we'll be spending more time learning about software testing. This week, we start off with an overview of different types of software testing.
Unit Testing
Guidance for the item(s) below:
Dependency Injection is a technique closely related to stubs. It is not in the syllabus but is given below in case some of you would like to know more about it.
Integration Testing
System Testing
Can explain automated GUI testing
If a software product has a GUI (Graphical User Interface) component, all product-level testing (i.e. the types of testing mentioned above) need to be done using the GUI. However, testing the GUI is much harder than testing the CLI (Command Line Interface) or API, for the following reasons:
- Most GUIs can support a large number of different operations, many of which can be performed in any arbitrary order.
- GUI operations are more difficult to automate than API testing. Reliably automating GUI operations and automatically verifying whether the GUI behaves as expected is harder than calling an operation and comparing its return value with an expected value. Therefore, automated regression testing of GUIs is rather difficult.
- The appearance of a GUI (and sometimes even behavior) can be different across platforms and even environments. For example, a GUI can behave differently based on whether it is minimized or maximized, in focus or out of focus, and in a high resolution display or a low resolution display.
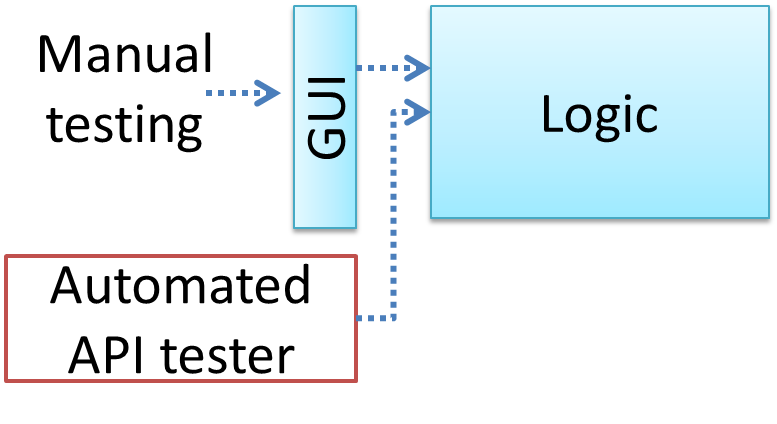
Moving as much logic as possible out of the GUI can make GUI testing easier. That way, you can bypass the GUI to test the rest of the system using automated API testing. While this still requires the GUI to be tested, the number of such test cases can be reduced as most of the system will have been tested using automated API testing.
There are testing tools that can automate GUI testing.
Some tools used for automated GUI testing:
TestFX can do automated testing of JavaFX GUIs
Visual Studio supports the ‘record replay’ type of GUI test automation.
Selenium can be used to automate testing of web application UIs
Acceptance Testing
Alpha/Beta Testing
Guidance for the item(s) below:
Previously, we learned how to measure test coverage. This week, we look into how to increase coverage with the least number of test cases.
First, we take a look at test case design in general, different approaches to test case design, and few different categorization of test cases.
Guidance for the item(s) below:
Next, a heuristic used for improving the quality of test cases.